
We introduce the basic ingredients of CA using a simple example. Think of an automaton as a one-dimensional grid of simple atomic elements (the cells), each of which can only instantiate one of two states; let us say that each cell can be turned on or off. The global evolution of the system is determined by a transition rule, to be thought of as implemented in each cell. Following the rule, at each time step each cell updates its status in response to what happens to its neighboring cells. As we said, CA are abstract: they can be described in purely mathematical terms. Having a concrete instance in mind can nevertheless help in the beginning:

Fig. 1
Think of Fig. 1 as standing for the front row of a high school classroom. Each box represents a student wearing (black) or not wearing (white) a hat. Let us make the two following assumptions:
Hat rule: a student will wear the hat in the following class if one or the other—but not both—of the two classmates sitting immediately on her left and on her right has the hat in the current class (let us say that if nobody wears the hat, then a hat is out of fashion; but if both neighbors wear it, it is too popular to be trendy).
Initial class: during the first class in the morning, only one student in the middle is wearing the hat (see Fig. 2).

Fig. 2
Fig. 3 shows what happens as time goes by (consecutive rows represent the evolution in time through subsequent classes):

Fig. 3
Fig. 3 may be surprising. The complex evolutionary pattern displayed contrasts with the simplicity of the underlying law (the “Hat rule”) and ontology (for in terms of object and properties, we only need to take into account simple atoms and two states). In a sense, though, the global, emergent behavior of the system supervenes upon its local, simple features. The scale at which the decision to wear the hat is made (immediate neighbors) is not the scale at which the interesting patterns become manifest.
While somewhat artificial, this example is a paradigmatic illustration of what makes CA appealing to a vast range of researchers: “even perfect knowledge of individual decision rules does not always allow us to predict macroscopic structure. We get macro-surprises despite complete micro-knowledge” (Epstein 1999, p. 48). Since the notion of emergence and the micro-macro interplay play such an important role in science and philosophy (see the entries on supervenience and emergent properties; for a sample of scientific applications, see Mitchell 2009, pp. 2–13, Gell-Mann 1994, Ch. 9), it has been suggested that many scientific as well as conceptual puzzles can be addressed by adopting the CA perspective. One of the leading thinkers in the field, Stephen Wolfram, has gone as far as claiming that CA may help us to solve longstanding issues in philosophy:
Among them [the fundamental issues philosophers address] are questions about the ultimate limits of knowledge, free will, the uniqueness of the human condition and the inevitability of mathematics. Much has been said over the course of philosophical history about each of these. Yet inevitably it has been informed only by current intuitions about how things are supposed to work. But my discoveries in this book [A New Kind of Science] lead to radically new intuitions. (Wolfram 2002, p.10)
In order to assess these bold claims, let us now take a closer look at the field.
1.2 An Overview of CA's CapabilitiesThe surprising patterns in the aforementioned classroom example were generated by small boxes in a line with just two states and a simple rule. One might wonder how many variations are possible on such a basic framework. In his review of the literature, Andrew Ilachinski narrows down CA applications to four main areas, which will be referred to in the rest of this entry (Ilachinski 2001, p. 7):
(CA1) As powerful computational engines.
(CA2) As discrete dynamical system simulators.
(CA3) As conceptual vehicles for studying pattern formation and complexity.
(CA4) As original models of fundamental physics.
(CA1) emphasizes that CA perform computations. Just like Turing machines, they can be fully specified in mathematical terms, and implemented in different physical systems. However, CA are peculiar in two important ways. First, unlike Turing machines (and the von Neumann-architecture conventional computers that implement them), they compute in a parallel, distributed fashion. Second, computation is pretty much “in the eye of the beholder”: there is no tape, but the evolution of the cells' states can often be interpreted as a meaningful computational procedure (e.g., bits can be encoded using the white/black cell states). Computational hardware inspired by CA can help in solving important technological problems (see Ilachinski 2001, p. 8), but apart from engineering issues, (CA1) also points to major conceptual questions, such as how exactly a universal Turing machine and an automaton can be compared and what are, if any, the philosophical implications of this comparison (see Wolfram 2002, Ch. 12).
(CA2) comprises scientific applications of CA to the modeling of specific problems—to mention just a few: urban evolution (Batty 2005), Ising models (Creutz 1986), neural networks (Franceschetti, Campbell, Hamneken 1992 pp. 124–128), and even turbulence phenomena (Chen, Chen, Doolen, Lee, 1983). As Ilachinski remarks, for instance, “discrete models of turbulence are particularly impressive in that they clearly show that very simple finite dynamical implementations of local conservation laws are capable of exactly reproducing continuum system behavior on the macroscale” (Ilachinski 2001, p. 8).
(CA3) and (CA4) enter more directly into the philosophical arena: as for (CA3), for instance, Daniel Dennett has resorted to a famous automaton we are to describe below, namely Conway's Game of Life, to make his point on determinism and the attribution of high-level concepts to emergent patterns (Dennett 1991, Dennett 2003). As for (CA4), CA can provide an account of microphysical dynamics by representing discrete counterparts of quantum field theories (see for example the entry on Quantum Field Theory) alternative to the standard continuous frames. But the more philosophical, and quite bolder, claim in this area is that nature itself may be a CA: Edward Fredkin, for instance, has advanced his “Finite Nature” hypothesis that our universe is an automaton which, at each time step, digitally and locally processes its state for the next time step (see Fredkin 1993). Apart from the interest generated by Fredkin's claim, entertaining the hypothesis raises a number of questions at the crossroads of physics and metaphysics (what is a natural law?), epistemology (what are the limits of physical systems predictability?) and the philosophy of information (what is the role of information in the physical world?). We will address each of these in the third Section of this entry.
1.3 A Brief HistoryWhile much of the computational framework in which CA are developed is indebted to the work of Alan Turing back in the Thirties (Turing 1936), it is fair to say that the father of CA is John von Neumann (von Neumann 1951). Working on self-replication and attempting to provide a reductionist theory of biological development, von Neumann was trying to conceive a system capable of producing exact copies of itself. Now biology prima facie intuitively appears to be the realm of fluidity and continuous dynamics. But following a suggestion of his colleague Stanislaw Ulam, von Neumann decided to focus on a discrete, two-dimensional system. Instead of just black-or-white cells, von Neumann's automaton used 29 different states and a rather complicated dynamics, and was capable of self-reproduction. Von Neumann's CA was also the first discrete parallel computational model in history formally shown to be a universal computer, i.e., capable of emulating a universal Turing machine and computing all recursive functions.
In the early Sixties, Moore (1962) and Myhill (1963) proved the Garden-of-Eden theorems stating conditions for the existence of so-called Gardens of Eden, i.e., patterns that cannot appear on the lattice except as initial conditions. Gustav Hedlund (1969), whose impact on computer science has been dramatic, investigated cellular automata within the framework of symbolic dynamics. In 1970 the mathematician John Conway introduced his aforementioned Life game (Berkelamp, Conway, Guy 1982), arguably the most popular automaton ever, and one of the simplest computational models ever proved to be a universal computer. In 1977 Tommaso Toffoli used cellular automata to directly model physical laws, laying the foundations for the study of reversible CA (Toffoli 1977).
Stephen Wolfram's works in the 1980s contributed to putting the growing community of CA followers on the scientific map. In a series of groundbreaking papers, Wolfram extensively explored one-dimensional CA, providing the first qualitative taxonomy of their behavior and laying the groundwork for further research. A particular transition rule for one-dimensional CA, known as Rule 110 was conjectured to be universal by Wolfram. Some twenty years after the conjecture, Matthew Cook finally proved that Rule 110 is the simplest known model capable of universal computation (Cook 2004) (Wolfram 2002 also contains a sketch of the proof).
2. Some Basic Notions and Results 2.1 Basic DefinitionsAfter our informal introduction, we are now going take a closer look at CA, focusing on models and results of philosophical interest. Although the variety of systems to be found in the CA literature is vast, one can generate virtually all CA by tuning the four parameters that define their structure:
- Discrete n-dimensional lattice of cells: We can have one-dimensional, two-dimensional, … , n-dimensional CA. The atomic components of the lattice can be differently shaped: for example, a 2D lattice can be composed of triangles, squares, or hexagons. Usually homogeneity is assumed: all cells are qualitatively identical.
- Discrete states: At each discrete time step, each cell is in one and only one state, σ ∈ Σ, Σ being a set of states having finite cardinality |Σ| = k.
- Local interactions: Each cell's behavior depends only on what happens within its local neighborhood of cells (which may or may not include the cell itself). Lattices with the same basic topology may have different definitions of neighborhood, as we will see below. It is crucial, however, that “actions at a distance” not be allowed.
- Discrete dynamics: At each time step, each cell updates its current state according to a deterministic transition function φ: Σn → Σ mapping neighborhood configurations (n-tuples of states of Σ) to Σ. It is also usually, though not necessarily, assumed that (i) the update is synchronous, and (ii) φ takes as input at time step t the neighborhood states at the immediately previous time step t − 1.
One can exhaustively describe, for instance, the automaton of our classroom example:
- 1-dimensional lattice of square cells on a line.
- Σ = {1, 0} (1 = black or hat on, 0 = white or hat off), so |Σ| = 2.
- Each cell's neighborhood is composed by the two nearest cells. If we index the cells by the integers, so that ci is cell number i, then the neighborhood of ci is N(ci) = <ci − 1, ci + 1>.
- The transition rule φ is simply stated: At each time step t, a cell state is 1 if exactly one of the neighboring cells was 1 at t − 1, 0 otherwise.
Natural language conditionals—such as ‘If the neighborhood is this-and-this, then turn to state s’—are a handy way of expressing a rule for a simple automaton. One can write more formally the general form of the rule for one-dimensional CA:
(Rule1D) σi (t + 1) = φ(σi − r(t), σi −r + 1(t), …, σi + r − 1 (t), σi + r(t))
Where σi(t) ∈ Σ = {0, 1, …, k − 1} is the state of cell number i at time step t; r specifies the range, that is, how many cells on any side count as neighbors for a given cell; and φ is defined explicitly by assigning values in Σ to each of the k2r+1(2r + 1)-tuples representing all the possible neighborhood configurations. For example, with r = 1, Σ = {1, 0}, a possible transition rule φ can be expressed as in Fig. 4 (with 1 being represented as black, 0 as white):

Fig. 4
For a given cell, each triple at the top represents a possible neighborhood configuration at t, the cell at issue being the one in the middle: for each configuration, the square at the bottom specifies the cell's state at t + 1. This is exactly the rule of our classroom example: you will have a black cell just in case precisely one of the neighbors was black.
2.2 The Wolfram Classification SchemeThis simple representation is also at the core of the widely adopted Wolfram code (Wolfram 1983), assigning to each rule a number: with black = 1 and white = 0, the bottom row can be read as a binary number (01011010); converting this number to decimal gives you the rule's name (in this case, Rule 90). Since rules for CA with r = 1 and k = 2 differ just in the bottom row of the diagram, this encoding scheme effectively identifies each possible rule in the class. One-dimensional CA with r = 1 and k = 2 are among the simplest CA one can define, yet their behavior is sometimes quite rich. When Stephen Wolfram started to explore this field in the Eighties, that class seemed a perfect fit. With r = 1, there are 8 possible neighbors (see Fig. 4 above) to be mapped to {1, 0}, giving a total of 28 = 256 rules. Starting with random initial conditions, Wolfram went on to observe the behavior of each rule in many simulations. As a result, he was able to classify the qualitative behavior of each rule in one of four distinct classes. Repeating the original experiment, we simulated the evolution of two rules for each class of Wolfram's scheme.
2.3 The Classes of the 256 RulesClass1—rules leading to homogenous states, all cells stably ending up with the same value:
| Rule 250 | Rule 254 |
 |
 |
Class2—rules leading to stable structures or simple periodic patterns:
| Rule 4 | Rule 108 |
 |
 |
Class3—rules leading to seemingly chaotic, non-periodic behavior:
| Rule 30 | Rule 90 |
 |
 |
Class4—rules leading to complex patterns and structures propagating locally in the lattice:
<!--pdf includepdf include-->
| Rule 54 | Rule 110 |
 |
 |
Class1 comprises the rules that quickly produce uniform configurations. Rules in Class2 produce a uniform final pattern, or a cycling between final patterns, depending on the initial configurations. The configurations produced by members of Class3 are pretty much random-looking, although some regular patterns and structures may be present.
Unsurprisingly, it was the members of Class4 that attracted Wolfram's attention. If we observe the universe generated by Rule 110 we see regular patterns (although not as regular as in Rule 108) as well as some chaotic behavior (although not as “noisy” as in Rule 90). Now the basic feature a CA needs to perform computations is the capacity of its transition rule of producing “particle-like persistent propagating patterns” (Ilachinski 2001, p. 89), that is, localized, stable, but non-periodic configurations of groups of cells that can preserve their shape (sometimes called solitons in the literature). These configurations can be seen as encoding packets of information, preserving them through time, and moving them from one spatial location to another: information can propagate in time and space without undergoing important decay. The amount of unpredictability in the behavior of Class4 rules also hints at computationally interesting features: by the Halting Theorem, it is a key feature of universal computation that one cannot in principle predict whether a given computation will halt given a certain input. These insights led Wolfram to conjecture that Class4 CA were (the only ones) capable of universal computation. Intuitively, if we interpret the initial configuration of a Class4 CA as its input data, a universal Class4 CA can evaluate any effectively computable function and emulate a universal Turing machine. As we mentioned above, Rule 110 was indeed proved to be computationally universal.
(See the supplementary document The 256 Rules.)
2.4 The Edge of ChaosThe intermediate nature of Class4 rules provided a powerful metaphor for the idea that interesting complexity, such as the one displayed by biological entities and their dynamics, lies in a delicate equilibrium between two extremes, “boring” regularities and “noisy” chaos:
Perhaps the most exciting implication [of CA representation of biological phenomena] is the possibility that life had its origin in the vicinity of a phase transition and that evolution reflects the process by which life has gained local control over a successively greater number of environmental parameters affecting its ability to maintain itself at a critical balance point between order and chaos. (Langton 1990, p. 13)
Since CA were able to provide not just the intuition, but a robust formal framework to investigate the hypothesis, in the late Eighties the “Edge of Chaos” picture received considerable interest by CA practitioners. Packard 1988 and Langton 1990 were the first studies to give to the Edge of Chaos a now well-known interpretation in the CA context. As Miller and Page put it, “these early experiments suggested that systems poised at the edge of chaos had the capacity for emergent computation” (Miller, Page 2007, p. 129). The idea is simple enough: what happens if we take a rule like Rule 110 and introduce a small perturbation? If we are to believe the Edge of Chaos hypothesis, we should expect the rules obtained by small changes in Rule 110 to exhibit either simple or chaotic behavior. Let us consider a single switch from 1 to 0 or 0 to 1 in the characteristic mapping of Rule 110. The results are the following eight neighboring rules, each differing from Rule 110 by a single bit (the diagonal in the array, with numbers in italics):
| 110 | 111 | 108 | 106 | 102 | 126 | 78 | 46 | 228 | |
| 000 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 001 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
| 010 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| 011 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| 100 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 101 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 110 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 |
| 111 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Class | 4 | 2 | 2 | 3 | 3 | 3 | 1 | 2 | 1 |
At a first approximation, the Edge of Chaos hypothesis is confirmed: three of the eight neighbors are Class3, three are Class2, two are Class1: Rule 110 is the only Class4 in the table. To generalize these findings to the entire class of rules for one-dimensional CA, Langton introduced a parameter, λ, that applies to each φ: for k = 2, r = 1 (binary-state, unary-range) CA, λ(φ) can be computed simply as the fraction of entries of the transition rule table that are mapped to a non-zero output (see Langton 1990, p. 14 for the general definition). What this means in our case is simple: λ(φ) will be equal to the number of ones in the rule column—e.g. λ(φ) = 5/8 for φ = Rule 110 and λ(φ) = 1/2 for φ = Rule 46. Langton's major finding was that a simple measure such as λ correlates with the system behavior: as λ goes from 0 to 1, the average behavior of the systems goes from freezing to periodic patterns to chaos. Langton singled out 1/2 as the value of λ at which the average behavior first shows evidence of chaos: rules φ with λ(φ) ∼ 1/2 were highlighted as being on the Edge (see Miller and Page 2001, p. 133).
| λ | All Rules | Chaotic Rules | Complex Rules |
| 0 | 1 | 0 | 0 |
| 1/8 | 8 | 0 | 0 |
| 1/4 | 28 | 2 | 0 |
| 3/8 | 56 | 4 | 1 |
| 1/2 | 70 | 20 | 4 |
| 5/8 | 56 | 4 | 1 |
| 3/4 | 28 | 3 | 0 |
| 7/8 | 8 | 0 | 0 |
| 1 | 1 | 0 | 0 |
Chaotic and complex rules both have an average λ value around 1/2, thus apparently supporting the Edge of Chaos hypothesis. It is fair to say, though, that some have cast doubts on the explanatory role of parameter λ and the inferences drawn from it. In particular, the transition region of the Edge of Chaos seems to be itself complex. Miller and Page note that “there are multiple edges, not just a single one” (Miller and Page 2007, p. 133). Aggregate results do not hold when we analyze individual rules, even paradigmatic ones:
| 110 | 111 | 108 | 106 | 102 | 126 | 78 | 46 | 228 | |
| λ | 5/8 | 3/4 | 1/2 | 1/2 | 1/2 | 3/4 | 1/2 | 1/2 | 3/4 |
As the table shows, among the Rule 110 neighbors, some chaotic rules φ have λ(φ) = 3/4, some cyclic ones have λ(φ) = 1/2 and, indeed, “every one of the rules classified as complex in this space has at least one chaotic neighbor with a lower λ value and one with higher value” (Miller, Page 2007, p. 135). Melanie Mitchell, Peter Hraber and James Crutchfield replicated Langton and Packard's experiments, reporting very different results (Mitchell, Hraber, Crutchfield 1994). In particular, they report that serious computational phenomena take place much closer to a chaotic λ(φ) = 1/2 than was previously thought. Apart from technical points, a main conceptual flaw in the original findings is the use of aggregate statistics, which are difficult to interpret in a high variance context: “if, instead, the hypotheses are concerned with generic, statistical properties of CA rule space—the ‘average’ behavior of an ‘average CA’ at a given λ—then the notion of ‘average behavior’ must be better defined” (Mitchell, Hraber, Crutchfield 1994, p. 14).
While it is fair to conclude that complex behavior does not lie at the Edge of Chaos taken in a simplistic sense (i.e., it is not straightforwardly correlated with the simple λ), the interest in the connection between computational capabilities and phase transitions in the CA rule space has been growing since then. We will consider such developments below, specifically in the context of CA and the philosophy of computation.
2.5 CA in More Dimensions: the Game of LifeNotwithstanding the computational interest of one-dimensional CA, philosophical issues have been discussed mostly in connection with two-dimensional CA. In fact the first CA, namely von Neumann's self reproducing automaton, inhabited a two-dimensional grid. Besides, two-dimensional CA are suitable for representing many physical, biological, and even human phenomena, ranging from the dynamics of perfect gases, to the movements of birds in a storm and soldiers on a battlefield. The most common configurations have either square or hexagonal cells, given their translational and rotational symmetries. Moving to two dimensions, of course, also expands the possibly interesting combinations of rules and neighborhoods. As for the latter, the two most common options in a grid of squares are the von Neumann neighborhood, where each cell interacts only with its four horizontal and vertical adjacent mates, and the Moore neighborhood, comprising all the eight immediately adjacent cells.
The best way to understand the two-dimensional perspective is again likely to be by way of example. We are therefore going to introduce the famous Game of Life (or, more briefly, Life) by John Conway (see Berkelamp, Conway, Guy 1982). In fact, Life fits well with our usual descriptive framework:
- 2-dimensional lattice of square cells in an orthogonal grid.
- Σ = {1, 0}, so |Σ| = 2 (we can intuitively picture 1 as the state of being alive for a given cell, 0 as the state of being dead, for reasons we are about to see).
- Each cell's neighborhood is composed of all its eight neighboring cells (the Moore neighborhood).
- Life's transition rule goes as follows. At each time step t exactly one of three things can happen to a cell:
- Birth: If the cell state at t − 1 was 0 (dead), the cell state becomes 1 (alive) if exactly three neighbors were 1 (alive) at t − 1;
- Survival: If the cell state at t − 1 was 1 (alive), the cell state is still 1 if either two or three neighbors were 1 (alive) at t − 1;
- Death: If the cell state at t − 1 was 1 (alive), the cell state becomes 0 (dead) if either fewer than two or more than three neighbors were 1 (alive) at t − 1 (cells can die of “loneliness” or “overpopulation”).
The simple Life rule makes of it a Class4 CA by Wolfram's taxonomy. In fact, this simple setting is a rich digital environment where periodic structures, stable blocks and complex moving patterns come into existence, even when the CA is set to start from a very simple initial configuration. As Conway remarked: “It's probable, given a large enough Life space, initially in a random state, that after a long time, intelligent, self-reproducing animals will emerge and populate some parts of the space” (cited in Ilachinski 2001, p. 131).
Life-fans in fact used to explore the CA's possible patterns of evolution, and to share their findings in what is known as Life's zoology (see e.g. Daniel Dennett's remarks in Dennett 2003, p. 41). We have collected a small gallery of samples together with snapshots of a typical simulation (for more pictures and animations, see the Internet references at the end). Gliders are the most popular among the basic Life inhabitants: a simple 5-bit structure, a glider can travel the Life grid in a 4-time step cycle and, thanks to its versatility, it is often among the basic building blocks of more elaborated structures.
| Glider | ||
 |
 |
 |
| t0 | t1 | t12 |
Toads are period 2 blinking configurations: together with Blinkers and Beacons they are the simplest “oscillators” of this universe.
<!--pdf includepdf include-->
| Toad | ||
 |
 |
 |
| t0 | t1 | t3 |
Eaters have the feature of devouring or eating other configurations, e.g. gliders, maintaining intact their form (and because of this, they play an important role for Life's computational abilities).
| An Eater devouring a Glider | ||
 |
 |
 |
| t0 | t2 | t4 |
A typical evolution of Life starting from random initial conditions may contain all of the above notable figures and much more. Some initial configuration may end up, even after few time steps, into static or simple periodic structures. Other configurations, though, can produce non-periodic, incresingly complex environments whose development can be unpredictable (even in the computational sense we are about to explore). As Ilachinski has suggestively conjectured from this:
Upon observing the seemingly unlimited complexity and variety of Life's evolving patterns, it becomes almost impossible to refrain from imagining, along with Conway, that, were the game really to be played on an infinite lattice, there must surely arise true living ‘life-forms’, perhaps themselves evolving into more complex, possibly sentient, ‘organisms’. (Ilachisnki 2001, p. 133)
 |
 |
 |
| t0 | t10 | t20 |
 |
 |
 |
| t30 | t40 | t175 |
The mathematical literature on CA does not refrain from describing the Life configurations using the same imaginative vocabulary we used, that is, in terms of items that are born, that live, move around, eat other figures, die, etc. The Life zoology, though, is in an important sense in the eye of the beholder: the universe these patterns inhabit can be more neutrally described as a collection of individual cells, each of which does not directly depend on what is happening on the macro-scale. Even more neutrally, Life can be described in the simple mathematical language of matrices and discrete sequences. But even if one is told the basic Life rule, one could hardly imagine the complexity it can generate—until one sees it. Life's reputation among scientists and philosophers arguably comes from its challenging naive intuitions about complexity, pattern formation, persistence, and continuity: as a toy universe we ourselves built, we feel we should know in advance what dynamics are allowed. This has been shown to be impossible, in a mathematically precise sense.
2.6 Life as a Universal Turing MachineLike any other CA, Life can be considered as a computational device: an initial configuration of the automaton can encode an input string. One can let the system run and, at some point, read the current configuration as the result of the computation performed so far, decoding it into an output string. But exactly what can Life compute? It turns out that Life can compute everything a universal Turing machine can and therefore, given Turing's Thesis, function as a general purpose computer: a suitable selection of initial conditions can ensure that the system carry out arbitrary algorithmic procedures.
The proof of the universal computational capacities of Life presented in Berkelamp, Conway, Guy 1982 consists in showing that the basic building blocks or primitives of standard digital computation can be emulated by appropriate patterns generated by Life—in particular: (a) data storage or memorization, (b) data transmission requiring wires and an internal clock, and (c) data processing requiring a universal set of logic gates, like negation, conjunction and disjunction—an actual Turing machine was later explicitly implemented in Life by Paul Rendell (see Rendell's own web page and MathWorld).
This finding is not of great engineering importance, (no one would spend their time translating “24 + 26 / 13” into Life). However, it raises a conceptual issue about any universe sharing the capacity of producing and hosting universal computers: because of the aforementioned Halting Theorem, there cannot be any general algorithm to decide whether, given an initial configuration as input, Life will eventually die out or halt. It is in this sense that the evolution of the automaton is unpredictable. Given that the development of CA that are computationally universal cannot be predicted by direct mathematical analysis alone, it is no surprise that CA practitioners have adopted the language of philosophy and talked of phenomenological studies of CA. Here the automaton is realized as a computer software, and the observable emergent properties of its evolution are empirically registered as the computer simulation advances. In Wolfram's turn of phrase, Life is algorithmically irreducible: no algorithmic shortcut is available to anticipate the outcome of the system given its initial input. “Life—like all computationally universal systems—defines the most efficient simulation of its own behavior”(Ilachisnki 2001, p. 15). This raises the important philosophical questions of the limits of the predictability of any universe—possibly our actual universe—which is itself capable, just as Life is, of producing and hosting universal computers.
2.7 Further CANotwithstanding the historical and conceptual centrality of the CA described in this section, many important developments in the field could not be presented in the space allowed for this entry. It is possible to relax some of the assumptions in the general characterization of CA provided in Section 2.1 and get interesting results. The transition rule, for instance, can be probabilistic and take into consideration more than just one time step (see Richards, Meyer, Packard 1990: probabilistic automata are widely used to represent the stochastic dynamics of microphysical systems); the cell state updating can be asynchronous (see Ingerson, Buvel 1984); the lattice can be made of non-homogenous cells following different transition rules (see Kauffman 1984); even the discreteness constraint can be relaxed by having the set of states be the set of real numbers (see Wolfram 2002, p. 155–157).
CA are also being fruitfully used in connection to the issue of the thermodynamic limits of computation: is there a minimum amount of energy needed to perform a logical operation? Landauer (1961) argued that irreversible logical operations (i.e., operations that, not corresponding to bijections, cannot be run backwards for they entail some information loss) necessarily dissipate energy. The invention of the Fredkin reversible logical gate and of the Billiard Ball Model of reversible computation (Fredkin and Toffoli 1982) strengthened the importance of the link between universal reversible automata and the physical properties of computation (for an overview, see Ilachinski 2001, pp. 309–323).
Finally, it is worth mentioning that genetic algorithms have been used with CA to study how evolution creates computation (for a survey of important results, see Mitchell, Crutchfield, Das 1996). While the aforementioned sources further explore these possibilities, the sample CA models discussed so far will be sufficient for the philosophical arguments we are going to address henceforth.
3. CA and PhilosophyA growing number of CA-related philosophical arguments are being produced, both by professional philosophers and by scientists interested in the conceptual implications of their work. Among the interesting issues already addressed through the CA approach in the philosophical market are the structure of emergence, free will, the nature of computation, and metaphysics in a digital world.
3.1 CA and EmergenceCA can be considered a paradigmatic locus for the study of phenomena related to emergence. Very roughly, the problem of emergence has to do with the appearance in a system of higher-level features and properties which, on the one hand, are clearly rooted in the basic, low-level properties of the system; but on the other hand, do not seem to be simply or mechanically obtainable from the latter (for an introduction, see the entry on Emergent Properties). The literature on CA has variously addressed the issue. On the one hand, being a low-level simple and controllable environment, CA present themselves as a natural framework for tackling the problem in its purest form. On the other hand, CA researchers have recognized how the systemic and global features of a complex CA system can be hard to predict even with perfect knowledge of low-level entities and laws:
Over and over again we will see the same kind of thing: that even though the underlying rules for a system are simple, and even though the system is started from simple initial conditions, the behavior that the system shows can nevertheless be highly complex. (Wolfram 2002, p. 28)
Due to the local nature of a CA's operations, it is typically very hard, if not impossible, to understand the CA's global behavior (…) by directly examining either the bits in the lookup table or the temporal sequence of raw 1–0 spatial configurations of the lattice. (Hordijk, Crutchfield, Mitchell 1996, p. 2)
One can divide the problem of emergence into two separate questions, roughly corresponding to epistemological and ontological issues: How can we recognize emergence? What is the ontological status of the high-level properties and features? As a matter of historical fact, CA have been invoked mainly to address the former. Epistemological issues have often been raised in connection with complex systems in general. In their open agenda for complex social systems, Miller and Page include the following question: “Is there an objective basis for recognizing emergence and complexity?” (Miller, Page 2007, pp. 233–234). The issue of detecting emergence is connected to the conceptual problems of defining what an emerging feature is. Only once we know what we are looking for can we scan the space-time evolution of a system and recognize its patterns.
Unsurprisingly, the emergent properties attracting CA scholars' attention have mainly been computational properties, i.e., the features enabling the system to perform complex calculations. Already in 1985 Wolfram was asking, “What higher-level descriptions of information processing in cellular automata can be given?”(Wolfram 1985, p. 181). Also in this case, in order to introduce the formal work on emergent CA computation and to compare these findings with the available philosophical accounts, we can start with a specific example. This is the “classification problem”. Here we want to design a one-dimensional automaton that answers a simple question: Are there more white or black cells at a given time t0? Starting from any initial conditions with more white (black) cells, the ideal automaton will halt having all its cells turned white (black) after a given number of time steps (designing an automaton that always gives the right answer is not feasible in practice; so the performance is judged by the fraction of random initial conditions that are correctly classified).
 |
 |
 |
| t0 | tn |
The task would be trivial for a standard serial computational device, but is far from trivial in a CA—precisely because of its turning on an issue of emergence. The answer requires a global perspective (how many cells are white (black) in the lattice as a whole?). However, the cells work with local rules: it seems that no single cell can do the counting. The ideal automaton should find a way to aggregate information from several parts of its own lattice to give the final answer: a kind of “emergent computation” is needed to successfully solve this density classification task. It has been proved that no CA can solve this problem precisely (see Land and Belew 1995). Since, however, CA with larger neighborhoods achieve better results in general, genetic algorithms are used to efficiently search the solution space (genetic algorithms are computational analogues of genetic evolution, in which a computational problem is addressed by producing, combining and selecting solutions to it; the details of the procedure as applied to the classification problem are not important for our purpose, though; for an accessible presentation see Mitchell 2009, p. 22; for a general introduction see Mitchell 1998). The following is a diagram of the “Rule φ17083”, discovered by James Crutchfield and Melanie Mitchell (Crutchfield, Mitchell 1995). The CA implementing the rule starts from an initial state with more white cells:
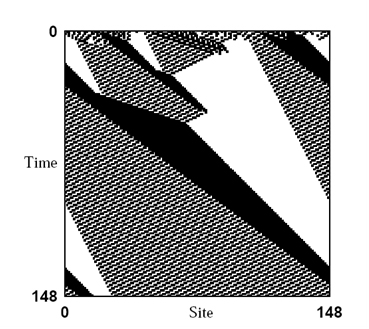
Fig. 5
At time step 250 (not shown in Fig. 5), the grey areas disappear and all cells end up white, i.e., the classification made by the automaton is correct. A high-level description of what is going on would have it that the white, black and grey regions that are “expanding”, “contracting”, “moving”, and by so doing manage to carry signals along the lattice. But how are we to explain the emergent computation CA of this kind perform? Building on previous works on computation theory applied to CA (Hanson, Crutchfield 1992, Crutchfield, Hanson 1993), Mitchell and Crutchfield filtered out from the original diagram what they call “domains”, i.e., dynamically homogenous spatial regions (Crutchfield, Mitchell 1995, p. 10745):
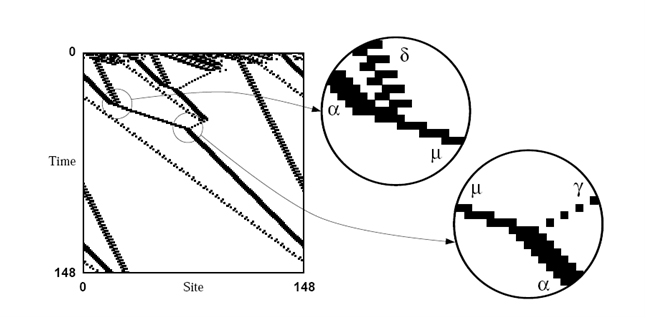
Fig. 6
Although in this case the “domains” are manifest, it is crucial to point out that their definition is rigorously mathematical. In fact, the whole process of domain-detection can be carried out algorithmically (see Hanson, Crutchfield 1992 for details). When the boundary of a domain remains spatially localized over time, then the domain becomes a “particle”:
Embedded particles are a primary mechanism for carrying information (…) over long space-time distances. (…) Logical operations on the signals are performed when the particles interact. The collection of domains, domain walls, particles and particle interactions for a CA represents the basic information processing elements embedded in the CA's behavior—the CA's “intrinsic” computation. (Crutchfield, Mitchell 1995, p. 10744)
There are five stable particles (termed α, γ, δ, ε, µ) and one unstable particle (β) for this automaton: their interaction (annihilation, decay, reaction) supports the emergent logic of the system. The two circles in the image above are examples of what may happen during an interaction. In the first case, α + δ → µ, a spatial configuration representing high, low, and then ambiguous densities is mapped to a high-density signal µ; in the second, µ + γ → α, a spatial configuration representing high, ambiguous, and then low density is mapped to an ambiguous-density signal α (Crutchfield, Mitchell 1995, p. 10745). The whole computational mechanics is worth exploring in more detail, but we can already safely generalize to the basic philosophical point of this and related works. According to O'Connor and Wong 2006, in the context of dynamic systems and the study of complexity emergence is characterized by most contemporary philosophers “strictly in terms of limits on human knowledge of complex systems. Emergence for such theorists is fundamentally an epistemological, not metaphysical, category” (O'Connor, Wong 2006, Sec. 2). But the Crutchfield-Mitchell approach suggests a different perspective. Firstly, the emergent computational properties in CA can in an important sense be objectively defined (see Crutchfield 1994a and the more accessible Crutchfield 1994b): although it is customary in this setting to talk of emergent computation being “in the eye of the beholder”, the detection and classification of patterns is itself algorithmic, not just phenomenological. Secondly, Crutchfield defines CA-emergence as a paradigmatic case of intrinsic emergence: the emerging patterns “are important within the system” (Crutchfield 1994b, p. 3), not merely important for an observer outside the system. More precisely, they are mathematically grounded on the basic features of the system, despite not being explicitly mentioned in its standard abstract characterization (Crutchfield mentions as non-intrinsic emergent phenomena the patterns in the Belousov-Zhabotinsky reaction and the energy recurrence in anharmonic oscillator chains reported by Fermi, Pasta and Ulam—see Crutchfield 1994b).
Crutchfield infers from this that many cases of emergence are indeed not reducible to some phenomenological interaction with an observer. They are genuine instances of an intrinsic phenomenon, not the results of some human-biased discovery (Crutchfield 1994b, p. 2). If emergence were not intrinsic, scientific activity would indeed be a subjective enterprise of “pattern discovery”:
Why? Simply because emergence defined without this closure leads to an infinite regress of observers detecting patterns of observers detecting patterns... (Crutchfield 1994b, p. 10)
Summarizing Crutchfield's work, Miller and Page say that the concept of emergence “has thus made the transition from metaphor to a measure, from something that could only be identified by ocular magic to something that can be captured using standard statistics” (Miller, Page 2007, p. 234).
Such remarks may sound philosophically naive to a trained epistemologist. It is not obvious, for instance, that the existence of a mathematical or specifically algorithmic emergent pattern would block a supposed regress entailed by a non-mathematical, or “merely phenomenological” emergence. Why would science as an activity of (occasionally) non-algorithmic pattern discovery be a merely subjective enterprise? If these claims can be re-phrased in a philosophically sophisticated way, though, they may challenge standard definitions of weakly emergent properties (in the sense of Chalmers 2002). Teller 1992, Clark 1996 and Bedau 1997, for instance, all run together instances of “pattern discovery”—a subjective, observer-dependent activity—with instances of intrinsic emergence—a phenomenon that, as we have just seen, can be characterized in the context of CA as objective and statistically significant (see the relevant Section of the entry on Emergent properties). Specifically, Bedau 1997 defines a macro-state emergent just in case it can be derived from knowledge of the system's micro-components only by direct simulation of the overall system evolution. Now, while the definition may work pretty well in the case of completely chaotic systems, it does not sit well with such CA as Rule φ17083. According to the proposed definition, the answer to the classification problem given by Rule φ17083 is an emergent phenomenon just in case the only way to go from t0 to tn is by explicitly simulating the system evolution.
|
|
|
| t0 | tn |
As it turns out, however, this is not the case. Using Crutchfield's particle model it is possible to predict the result of the classification by simply making particle-calculations, without bothering about the underlying dynamics (Hordijk, Crutchfield, Mitchell 1996). Here then, the emerging computation in the CA would not be a case of emergence for Bedau.
What are the ontological consequences of this? While emerging patterns in CA have been examined both by reductionist (Dennett 2003) and emergentist philosophers (Thompson 2007), it is fair to say that the CA literature so far has not significantly contributed to the ongoing philosophical debate on the purely ontological side of reductionism. CA patterns that are “objectively” detected via computation, as per the Mitchell-Crutchfield approach, are not ipso facto new primitives to be included in an ontology. It may well be that features of a CA that are objective, in the sense of not depending on the interaction with an observer, are nevertheless ontologically reducible to more basic entities via suitable definitions (see Kim 1999, Dennett 1991).
3.2 CA and Free WillPhilosophers have debated the relationship between determinism and free will for over two millennia. Two opposite stances can be taken towards the problem: compatibilism maintains that free will is compatible with a deterministic world, which incompatibilism denies (see the entries on Free will and Compatibilism). Surprisingly enough, Daniel Dennett and Stephen Wolfram both argued that adopting the CA perspective can provide a solution, or perhaps a dissolution, of the longstanding mystery of free will.
Daniel Dennett has claimed that Life “renders vivid and robust a set of intuitions that are otherwise absent” (Dennett 2003, p. 40). According to Dennett, a major obstacle to accepting compatibilism is our deeply rooted persuasion that determinism implies inevitability, thus excluding free will (Dennett 2003, p. 25). We may thus make compatibilism palatable by exhibiting an intuitive counterexample to that conviction: a deterministic world in which, however, not everything is inevitable, i.e., something is avoidable (Dennett 2003, p. 56). Dennett maintains that CA can do this. He takes Life as a vivid illustration of how, in a deterministic but complex enough world, we can abstract away from the bottom level and the micro-laws deterministically governing it, and describe what is happening by taking the emergent level seriously. Recall the eater-glider dynamics:
|
|
|
| t0 | t2 | t4 |
At t0, an observer aiming at predicting the evolution of this space-time region has basically two choices: she can take into account (what Dennett calls) the physical level, and compute pixel by pixel the value of each cell state at each time step; or, she can focus on the design level, and employ high-level concepts such as those of glider and eater to ground her predictions (Dennett 2003, p. 39). The first option is perfectly deterministic, but has a flaw: it is time consuming, in such a way that, by the time you have made the required computation, the world has already evolved (this is especially true of a universal CA—as we have already hinted at above, and shall expand on soon). The second option is much faster: you know without much calculation what is going to happen to a glider meeting an eater. The predictions though, cannot be 100% reliable:
Whereas at the physical level, there are absolutely no exceptions to the general law, at the design level our generalizations have to be hedged: they require “usually” clauses (…). Stray bits of debris from earlier events can “break” or “kill” one of the objects in the ontology at this level. Their salience as real things is considerable, but not guaranteed. (Dennett 2003, p. 40)
Dennett's point is that avoidance itself is a high-level concept. As such, it is compatible with a deterministic bottom level (because the concepts at the emergent level are, by design, independent from the micro-laws). The physical description and the design description of Life are different interpretations of the same basic ontology, namely, the sparse ontology of CA. While in theory we could avoid the introduction of emergent concepts, in practice it is only by speaking of gliders, movements and avoidance that we can make sense of the evolution of the system (Dennett 2003, pp. 43–44). Even without knowing Life's physics, we could do a good job if we predicted the future by mentioning only high level patterns. Life is just a toy universe but, Dennett claims, these new intuitions are sufficient to see that, in some deterministic worlds, something is avoidable. For instance, it is true at the design level that gliders actually avoid eaters. Thus, the inference from determinism to inevitability can be blocked.
A standard reply to Dennett's argument consists in denying that Life-avoidance is “real” avoidance. Dennett himself puts a version of this argument in the mouth of Conrad, a fictional skeptic philosopher discussing Dennett's idea throughout his book:
It may look like avoidance, but it's not real avoidance. Real avoidance involves changing something that was going to happen into something that doesn't happen. (Dennett 2003, p. 58)
Rephrasing Dennett's example, we can identify an ambiguity in Conrad's argument. Imagine that a baseball is going to hit you in the face—but you dodge it: a clear case of real human avoidance. In what sense was the baseball “going to” hit you in the face? (Dennett 2003, p. 59) One might say that it was never really going to hit you, precisely because it triggered the reaction of whatever “avoidance system” you have. What is the difference between this avoidance and Life-avoidance? For Dennett, this is not a difference in kind, but in complexity: gliders and humans both have avoidance systems, but human systems are much more sophisticated. The choice of a universal CA as a toy universe allows us to draw a stronger conclusion: since we know that Life is equivalent to a universal Turing machine, as was explained above, some patterns in that universe may display avoidance systems at least as complex as ours. Dennett claims that compatibilism has thus won the first round: “you agree that (…) I've shifted the burden of proof: there shall be no inferring inevitability in any sense from determinism without mounting a supporting argument” (Dennett 2003, p. 61).
Stephen Wolfram addresses the phenomenon of free will in his book on CA:
From the discoveries in this book it finally now seems possible to give an explanation for this [free will]. And the key, I believe, is the phenomenon of computational irreducibility. (Wolfram 2002, p. 750)
We have introduced the issue of computational (or algorithmic) irreducibility when we explained the philosophical consequence of a universality proof for an automaton, namely that, although a system follows definite underlying laws, “its overall behavior can still have aspects that fundamentally cannot be described by reasonable laws” (Wolfram 2002, p. 750). The only way to predict the system's behavior is to perform step by step all the micro-computations. In this “separation between the underlying rules for the system and its overall behavior” (Wolfram 2002, p. 751) lies the secret of free will, since it seems that we attribute free will to a system just when “we cannot readily make predictions about the behavior of the system” (Wolfram 2002, p. 751). According to Wolfram, CA play a leading role in providing a new framework to understand the phenomenon. While explanations from chaos theory and quantum randomness have recently been proposed (see the entry on Chaos), “nothing like this is actually needed” (Wolfram 2002, p. 752). By observing CA, we can understand how something with simple and definite micro-rules, like those governing our neurons, can produce a behavior free of obvious rules: “the crucial point is that this happens just through the intrinsic evolution of the system—without the need for any additional input from outside or from any sort of explicit source of randomness”(Wolfram 2002, p. 752). Wolfram's point is similar to some of Dennett's remarks, namely: taking some sort of “design stance”, Wolfram suggests that one can talk about a cellular automaton as it just “decides” to do this or that—“thereby effectively attributing to it some sort of free will” (Wolfram 2002, p. 752).
How important are CA to these accounts? Dennett and Wolfram both use CA as intuition pumps. However, their positions seem to be slightly different. For while the former sees CA as a “useful toolkit” to develop intuitions and vividly illustrate his arguments (Dennett 2003, p. 40), the latter claims that CA provides a “new kind of intuition”, one that “no branch of everyday experience” could provide (Wolfram 2002, p. 41).
The importance Wolfram attaches to CA seems to rely on a single, generic “indispensability argument” to the conclusion that CA justify the foundation of “a new kind of science” (Wolfram 2002, pp. 7–16). We can reconstruct this argument as follows:
(NKS1) The observation of CA evolution leads to a scientific discovery: “very simple rules produce highly complex behavior” (Wolfram 2002, p. 39).
(NKS2) This discovery—the “new intuition”—promises to explain old and new phenomena and uncover important regularities.
(NKS3) Therefore, the core of our current scientific practices (based on the “old intuition”) should be radically changed to accommodate this discovery.
(NKS1) is to be taken at face value. It entails that the concepts involved were not previously known. Wolfram talks in terms of “the single most surprising scientific discovery I have ever made” (Wolfram 2002, p. 27). Is (NKS1) true? For sure, the idea that a deterministic and simple system may produce unpredictable behavior started circulating in the scientific community well before Wolfram's work. Signs of what is now chaos theory can be traced backed to the 19th and early 20th century, e.g., to the work of Poincaré 1914. One might grant that CA allowed the discovery that simple systems may produce complex behavior via the proof that they have unpredictable emergent computational complexity (although this discovery itself, as outlined in our brief historical section, was not made but only greatly publicized by Wolfram). Why has this discovery not been made earlier? Wolfram's own diagnosis is twofold: on the one hand, we have the “engineering” intuition that to produce something complex we should build something complex—that's because this is how ordinary machines work. On the other, CA were not obviously connected to any established discipline, and therefore they were not studied in academic circles.
As for (NKS2), we just examined the case of free will. In Wolfram's perspective, free will looks just like another puzzling philosophical phenomenon explained away by the advance of (a new kind of) science. Just as life was puzzling before the discovery of the double helix, free will was puzzling before the discovery of a suitable scientific theory, one that can finally account for the separation between micro and macro level. Many reductionist philosophers are no strangers to this kind of argument. The concepts and intuitions used in contemporary philosophy are often rooted in current scientific practices. When groundbreaking discoveries are made, old arguments may be revised: troublesome concepts become harmless and new challenges are introduced. From this perspective, Wolfram's account of the free will problem may lack philosophical rigor, but it is a promising start to re-address the challenge armed with new scientific models of determinism and complexity—pretty much as Dennett does. While many successful applications are needed to fully vindicate (NKS2), our first assessment concludes that, at the very least, it is not obviously false. As for the “new regularities” promised by (NKS2), we will address them in the next section.
3.3 CA and the Philosophy of ComputationCA are computational systems that perform complex tasks on the basis of the collective behavior of simple items. What, if anything, does it tell us about the importance of computation for systems in nature?
Different conclusions have been drawn by practitioners in the field. Some have endorsed the more modest claim that the computational features of CA are important to understand and compare social, biological, and physical systems modeled by them; but others have taken CA to support the view that computation and information processing in a discrete setting lie at the very foundations of reality. We will explore the stronger claim in Section 3.4 below. As for the weaker claim, it is not possible here to address the general importance of computational properties across the sciences (see Mitchell 2009, pp. 169–185). We will focus instead on a specific, and controversial, principle put forward by Stephen Wolfram, the so-called “Principle of Computational Equivalence”:
There are various ways to state the Principle of Computational Equivalence, but probably the most general is just to say that almost all processes that are not obviously simple can be viewed as computations of equivalent sophistication. (Wolfram 2002, pp, 716–717)
The Principle is the most fundamental law of Wolfram's New Kind of Science, as well as a prominent regularity featured by (NKS2): “its implications are broad and deep, addressing a host of longstanding issues not only in science, but also in mathematics, philosophy and elsewhere” (Wolfram 2002, p. 715). Contrary to Wolfram's claims, the Principle may not be new to philosophy at all. That “all processes can be viewed as computations” (Wolfram 2002, p. 715) has often been argued for in the history of philosophy, just as the claim that universal computation is a widespread phenomenon in the natural world (see e.g. Searle 1992, Putnam 1988 and the entry on Computation in Physical Systems). However, Wolfram's explanation of the Principle includes two further, and more specific, statements: i) No natural system can compute more things than a universal digital computer (see Wolfram 2002, p. 730), that is, “universal computation is an upper limit on the complexity of computation” (Mitchell 2009, p. 157); and ii) The computations performed by natural systems are essentially equivalent in sophistication (see Wolfram 2002, pp. 719–726).
The first point is relevant once we compare digital computation with the idea of a computer working with real numbers in continuous time. It has been proved (see Moore 1996) that such a device would be able to compute more functions than a traditional Turing machine. However, proponents of a discrete space-time like Wolfram treat continuous processes as, in a sense, epiphenomenal, since they already have independent reasons (some of which will be addressed below) to believe in a fundamentally discrete universe. As for the second point, its main problem is that the interpretation of “equivalent sophistication” is not straightforward. For even assuming that universal computation is widespread, it does not seem to follow that all computation is equivalent in sophistication. Complexity scientists, even after having agreed with Wolfram on the importance of computation for social, biological and physical systems, and even on the extent to which universal computation is supported in nature, are puzzled by his claim:
I find it plausible that my brain can support universal computation (…) and that the brain of the worm C. elegans is also (approximately) universal, but I don't buy the idea that the actual computations we engage in, respectively, are equivalent in sophistication. (Mitchell 2009, p. 158)
It is not clear what to make of computational equivalence. Yes, there is a threshold in which systems are related to one another, but given the difficulty of moving among them, is this any more useful than saying that skateboards and Ferraris are equivalent means of moving about? (Miller, Page 2007, p. 232)
Miller and Page argue that, for all scientific purposes, “representations do matter, and what can be easily computed in one system is often difficult (but still possible) to compute in another”. Even if Wolfram is right when he claims that a simple automaton can calculate the first few prime numbers (Wolfram 2002, p. 640), the calculation we have to do to encode the input and decode the output is very complex:
This latter calculation could be much more “difficult” to compute than the original problem, just as the complexity of a compiler can far exceed the complexity of the programs it produces. (Miller, Page 2007, p. 232)
Moreover, a rationale for studying CA is that they solve some computational problems more efficiently than standard computers (Ilachinski 2001, p. 8). Unless Wolfram's notion of “equivalent sophistication” simply means “they compute the same functions”—in which case, the claim is a truism—, the Principle cannot explain this empirical difference. The Principle may have a more substantive reading if understood as a metaphysical thesis about the universe in general, not as a scientific generalization having merely heuristic value. Under this stronger reading, the Principle is no more concerned with particular systems that can be fruitfully analyzed via computation theory, but with the fact that (different epistemological properties notwithstanding) the world itself is a computer. In a sense, any system would just be the emergent manifestation of a unique, underlying computational reality. Which naturally leads us to finally address the boldest question: What if the universe itself was a CA?
3.4 CA as Models of RealityIn the last fifty years various scientists (see Zuse 1982, Fredkin 1993, Wolfram 2002) have explicitly advanced a bold conjecture: that the physical universe is, fundamentally, a discrete computational structure. Everything in our world—quarks, trees, human beings, remote galaxies—is just a pattern in a cellular automaton, much like a glider in Life. We can single out two main reasons to investigate this provocative claim. First, the arguments put forward to support the view may be philosophically interesting in themselves. Second, the ontological structure of a CA-world can be fruitfully compared to existing metaphysical accounts. Let us take each point in turn.
The picture of nature as a CA is supported by an epistemological desideratum, i.e., having exact computational models of the physical world (see for instance the discussion of ontic pancomputationalism in Computation in Physical Systems). While this is certainly one of the arguments involved, it is not the only one and probably not the strongest. As Piccinini points out, even someone who shares that desire “may well question why we should expect nature to fulfill it” (Piccinini 2010, Section 3.4).
Ilachinski proposes a different “argument from epistemology” (Ilachinski 2001, pp. 661–2). Let us consider again the space-time diagram of Rule 110:

Fig. 7
Let us imagine we ignore its being generated by the iteration of a simple local rule, or even that it is an automaton. Then, says Ilachinski:
Noticing that the figure consists of certain particle-like objects sprinkled on a more-or-less static background, the simplest (most natural?) thing for you to do (…) is to begin cataloging the various “particles” and their “interactions.” (…) What you almost assuredly will not have, is any idea that the underlying physics really consists of a single—very simple—local deterministic rule(…). How different is this alien two-dimensional world from our own? (Ilachinski 2001, p. 662).
This highlights how CA may generate situations that we naturally view as physically realistic. A philosopher would consider this more as a suggestion than as a full-fledged argument: that we cannot rule out a priori our universe's being, at its bottom level, a CA does not entail that it actually is a CA.
A firmer ground to explore the hypothesis comes from some independent reasons of theoretical dissatisfaction with contemporary physics. We will limit ourselves to what we may call conceptual complaints, as opposed to ones more closely related to scientific practice, such as the failure of reductions of quantum mechanics and relativity to a Theory of Everything. We will examine the following three: (i) the problem of infinity, (ii) the need for a transparent ontology,(iii) the physical role of information.
As for complaint (i): while infinite and infinitesimal quantities provide us with powerful tools to model and advance predictions on the physical world, it remains controversial what ontological conclusions should be drawn from this fact. Since Zeno's Paradox (see the related entry) the continuity of space-time, as well as other fundamental physical variables, have puzzled philosophers and scientists alike. In the words of the physicist Richard Feynman:
It bothers me that, according to the laws as we understand them today, it takes a computing machine an infinite number of logical operations to figure out what goes on in no matter how tiny a region of space, and no matter how tiny a region of time. How can all that be going on in that tiny space? Why should it take an infinite amount of logic to figure out what a tiny piece of space-time is going to do? So I have often made the hypothesis that ultimately physics will not require a mathematical statement, that in the end the machinery will be revealed and the laws will turn out to be simple, like the checker board with all its apparent complexities. (Feynman 1965)
One way theoretical physicists have approached the problem has been to postulate a further reality, one that is below what is described by current physics. This fundamental layer of reality has often been conceived along the lines of Edward Fredkin's “Finite Nature Hypothesis”:
Finite Nature is a hypothesis that ultimately every quantity of physics, including space and time, will turn out to be discrete and finite; that the amount of information in any small volume of space-time will be finite and equal to one of a small number of possibilities. (…) We take the position that Finite Nature implies that the basic substrate of physics operates in a manner similar to the workings of certain specialized computers called cellular automata. (Fredkin 1993, p. 116)
If a cellular automaton is a model satisfying this hypothesis, then “underneath the laws of physics as we know them today it could be that there lies a simple program from which all the known laws (…) emerge” (Wolfram 2002, p. 434). If there currently is no way of saying if physics is fundamentally continuous or discrete, at least the Finite Nature Hypothesis seems to be a no less falsifiable prediction (see Fredkin 1990) than many speculative metaphysical pictures. Unfortunately, although we have attempts to recapture field theory within CA theory (see e.g. Svozil 1987, Lee 1986), there is no agreed-upon derivation of today's continuous physics within a CA framework; it is therefore safe to say that no party has a clear advantage here.
As for complaint (ii): one reason to adopt the view of CA as models of a fundamentally discrete world is the desire for a transparent ontology. Take a materialist philosopher for whom the task of physics is to provide an ultimate description of reality on the basis of a handful of basic physical properties and relations. In this perspective, a CA-based physics may provide a neat and elegant ontological picture: one that would be describable in a first-order formal theory including the axioms of standard mereology (even of mereotopology, as presented e.g. in Casati, Varzi 1999), and whose theorems would be computable in finite time (see Berto, Rossi, Tagliabue 2010, pp. 73–87). Besides, CA make easier to reconcile seemingly contradictory properties of different physical laws, such as the reversibility of micro-laws and the irreversibility of the Second Law of Thermodynamics (see for example Wolfram 2002, pp. 441–457 and Berto, Rossi, Tagliabue 2010, pp. 43–46).
As for point (iii), concerning the physical role of information: CA can accommodate a hypothesis endorsed by a growing number of scientists and philosophers, namely that information is not just one aspect of the physical world, but, in a sense, the most fundamental. For instance, Fredkin's Finite Nature Hypothesis not only stresses the importance of the informational aspects of physics, but “it insists that the informational aspects are all there is to physics at the most microscopic level” (see Fredkin 1993).
One way in which this idea has been developed is the so-called “it from bit” theory (see for example Wheeler 1990). In David Chalmers' words, this approach “stems from the observation that in physical theories, fundamental physical states are individuated as informational states” (Chalmers 1996, p. 302). Physics is silent on what accomplishes the specified functional roles, so “any realization of these information states will serve as well for the purpose of a physical theory” (Chalmers 1996, p. 302). The “it from bit” approach is particularly appealing to Chalmers (as a philosopher of mind committed to qualia being intrinsic, non-reducible properties) because it allows for a simple unification: we need intrinsic properties to make sense of conscious experience, and we need intrinsic properties to ground the informational states that make up the world's physics. If we claim that all the informational states are grounded in phenomenal (or proto-phenomenal) properties, we “get away with a cheap and elegant ontology, and solve two problems in a single blow” (Chalmers 1996, p. 305). The cell states in a CA fit the bill: if we interpret them as proto-phenomenal properties, we obtain the intrinsic structure of some sort of computational neutral monism (for an historical introduction, see the related entry)
Albeit individually controversial, taken together the three points support a simple and elegant metaphysical picture which is not evidently false or incoherent. Supposing that the actual physical world is a giant, discrete automaton, are there philosophically interesting conclusions to be drawn?
A first conclusion has already been partially explored in connection with Life: if nature is a CA, it has to be a universal CA, given that universal computers (e.g., the one on which you are reading this entry) uncontroversially exist in the physical world. Then its evolution is algorithmically irreducible, given the Halting Problem. Notwithstanding the opportunity of devising approximate forecast tools, we are left with a universe whose evolution is unpredictable for a reason quite different from the ones commonly adduced by resorting to standard physics, such as quantum effects or random fluctuations: it is unpredictable just because of its computational complexity.
A second philosophical topic is the connection between a CA-world and one of the most famous contemporary metaphysical theses, namely David Lewis' Humean Supervenience (HS). Using Ned Hall's characterization, we can state HS as the collection of these four claims about the structure of our world:
(HS1) There are particulars (space-time points).
(HS2) They are, or are wholly composed of, simples — particulars that have no other particulars as parts.
(HS3) These simples have various perfectly natural monadic properties.
(HS4) They stand in various spatiotemporal relations to one another.
If we substitute “space-time points” with “cells”, HS gets very close to a CA ontology: cells are arranged in a lattice, have various spatiotemporal relations to one another (e.g., being a neighborhood of), and have monadic properties (states) which can be considered perfectly natural, i.e., the basic properties out of which any other can be construed. A CA universe is thus a prima facie abstract model of Lewis' HS and can be fruitfully used to illustrate Lewis' original point, which was a reductionist one:
The point of defending Humean Supervenience is not to support reactionary physics, but rather to resist philosophical arguments that there are more things in heaven and earth than physics has dreamt of. (Lewis 1994, p. 474).
There are, however, two differences between the ontology naturally suggested by CA theories and Lewis' view. First, for Lewis space-time is an essentially continuous, four-dimensional manifold, eternalistically conceived (see the entry on eternalism and four-dimensionalism for an introduction), while in a standard CA-driven ontology, it is not. Second, Lewis reduces laws of nature to particulars while, as we have seen in Section 2 above, CA rules are always included as a further specification of the model.
The first disagreement may not be very substantial. A CA-world is compatible, for instance, with an eternalist conception. The idea that the world's next state is computed at any time step can be seen as a merely heuristic device, a “shortcut” for a more proper eternalist description in which the cell's states are once and for all “stuck” in their space-time position (we did this ourselves when describing the first picture in this section as the complete space-time evolution of a micro-universe).
The second disagreement concerning the laws of nature, on the other hand, may be a thorny issue. According to Lewis 1973, laws of nature are the true generalizations found in the deductive system that best describes our world (where “best” basically refers to the optimal trade-off between strength and simplicity; see the related entry for an introduction to, and further details on, this debate): laws of nature supervene on the four-dimensional arrangement of particulars and their properties. To the contrary, the standard description of a CA does not take the space-time evolution for granted: it takes the automaton's initial conditions as given, and generates the system evolution over time via the CA transition function. Particulars depend on laws, not vice versa. A CA world is not laid out in advance, but it grows as long as the laws are applied to particulars (a similar point is also made in Wolfram 2002, pp. 484–486).
On the other hand, one may tentatively interpret, in Lewisian fashion, the laws of a CA as the generalizations contained within the deductive system that best describes the CA behavior. Let us consider one last time our micro-universe from Rule 110:
A suitable deductive system for this space-time diagram may be obtained with just two axioms, one stating the initial conditions of the system, and one phrased as a conditional expressing the CA transition rule. If this conditional is a true generalization embedded in the deductive system that best describes our toy universe, then Rule 110 can count as a Lewisian law of nature in this universe, as expected.
4. Concluding RemarksAlthough some CA topics are still relatively untouched by philosophers (e.g., the nature of space and time (see Wolfram 2002, pp. 481–496), the representation of knowledge in Artificial Intelligence (see Berto, Rossi, Tagliabue, pp. 15–26), the relationship between information and energy (see Fredkin, Toffoli 1982)), there are many conceptual challenges raised in connection with CA. While in some cases the CA contribution was indeed overrated by practitioners, in others CA proved to be useful and transparent models of important phenomena.
As a final comment: what is left, from a purely scientific perspective, of the NKS Argument? Let us go through it again:
(NKS1) The observation of CA evolution leads to a scientific discovery: “very simple rules produce highly complex behavior” (Wolfram 2002, p. 39).
(NKS2) This discovery—the “new intuition”—promises to explain old and new phenomena and uncover important regularities.
(NKS3) Therefore, the core of our current scientific practices (based on the “old intuition”) should be radically changed to accommodate this discovery.
Even granting the truth of the two premises (that is, even granting the troublesome Principle of Computational Equivalence), it is doubtful the desired conclusion would follow. Surely, CA have provided new intuitions and explanations for a set of phenomena—Wolfram quite succesfully applies his “discovery” to biology, computer science, physics, finance. However, there is no evidence that many of our best scientific explanations will soon be reduced to the CA framework, and indeed many aspects of complexity itself still lie outside the CA paradigm, with no unification in sight. Paradigm shifts usually require the new paradigm to explain the same phenomena the old one did, and some more. CA are a promising field, but many developments are still needed for (NKS3) to be true.





